 OpenDance: Multimodal Controllable 3D Dance Generation with Large-scale Internet Data
OpenDance: Multimodal Controllable 3D Dance Generation with Large-scale Internet Data
Abstract
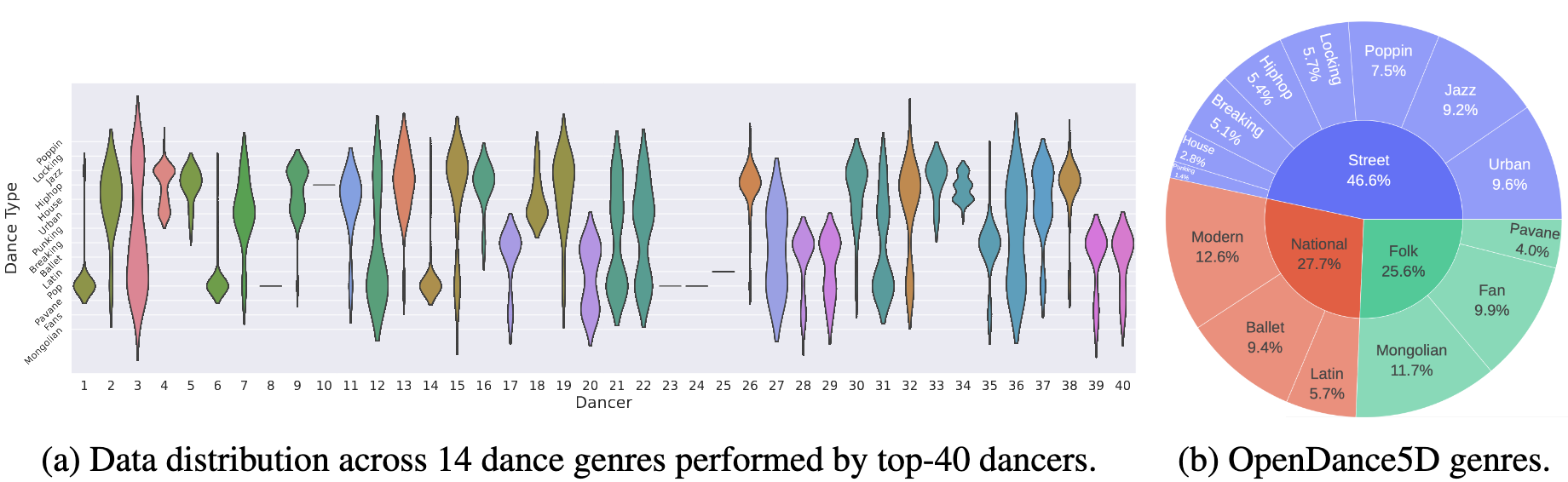
Music-driven 3D dance generation offers significant creative potential, yet practical applications demand versatile and multimodal control. As the highly dynamic and complex human motion covering various styles and genres, dance generation requires satisfying diverse conditions beyond just music (e.g., spatial trajectories, keyframe gestures, or style descriptions). However, the absence of a large-scale and richly annotated dataset severely hinders progress. In this paper, we build OpenDanceSet, an extensive human dance dataset comprising over 100 hours across 14 genres and 147 subjects. Each sample has rich annotations to facilitate robust cross-modal learning: 3D motion, paired music, 2D keypoints, trajectories, and expert-annotated text descriptions. Furthermore, we propose OpenDanceNet, a unified masked modeling framework for controllable dance generation, including a disentangled auto-encoder and a multimodal joint-prediction Transformer. OpenDanceNet supports generation conditioned on music and arbitrary combinations of text, keypoints, or trajectories. Comprehensive experiments demonstrate that our work achieves high-fidelity synthesis with strong diversity and realistic physical contacts, while also offering flexible control over spatial and stylistic conditions.

Dataset Demos
Visualization case #1
Visualization case #2
Visualization case #3
Visualization case #4
Dataset Quality Comparison
Side-by-side comparison between AIST++ and OpenDance samples.
AIST++
OpenDanceSet
Condition-Controlled Generation (Watch in Full Screen)
Comparison between full multimodal control and keypoints-only guidance.
Music + All Controls
Music + Keypoints Only
Multimodal Condition Controllability
🎵 Videos with music (sound on) 🎵
Music only
Music + All Conditions
Music + Kpts2D
Music + Global Position
Music + User-defined Signals
(More demos coming soon...)
🎵 Videos with music (sound on) 🎵
Straight Line (Input: start + end positions)
Circle Line (Input: start position, radius, and center)
Different Characters Dance Now
🎵 Videos with music (sound on) 🎵
OpenDanceNet Generation Demos
🎵 Videos with music (sound on) 🎵
(trained on OpenDanceSet dataset, with multimodal condition)
(trained on AIST++ dataset, without multimodal condition)